In my previous job, I conducted multiple technical interviews, and one of the key questions we asked candidates was:
“If you have a database and a query takes longer than required to run, what would you do?”
After discussing their response, we would follow up with:
“Now, what if the load on your database increases? What would you do now?”
This question helped assess whether the candidate could scale a database effectively without over-engineering. An immediate mention of CQRS in the first round was often a red flag—indicating they skipped simpler solutions and jumped to complex ones. We also valued candidates who asked clarifying questions before proposing solutions. Jumping into an answer without knowing the QPS (queries per second) or required response time was another bad sign.
Recently, I watched two insightful lectures by Martin Kleppmann, the author of Designing Data-Intensive Applications:
These lectures structured many of the concepts I already knew about database scaling and highlighted the importance of immutable data and stream-based architectures like Apache Kafka. Inspired by this, I decided to answer the same interview question myself.
Optimizing Queries Before Scaling
Interviewer: Imagine you have a query:
SELECT * FROM users WHERE email = 'something@somewhere.com'
and it is running slower than expected. What would you do?
My first step would be to gather more context:
- What is the expected vs. actual response time?
- Does this happen all the time or only during peak load?
- Could this be due to network latency instead of database performance?
Interviewer: It’s not a network issue, and the slow response happens consistently.
The simplest optimization is adding an index. In this case, an index on the email column would reduce lookup time from O(n) to O(log n).
Interviewer: This field already has an index.
If indexing isn’t the issue, I’d investigate whether the QPS has increased—high traffic can slow down even well-optimized queries.
Handling High Load
Interviewer: How would you determine if high QPS is the issue, and what would you do in each case?
I’d use monitoring tools to check query performance metrics. If QPS is stable, I’d analyze the query execution plan (EXPLAIN <query>) to identify bottlenecks.
If high QPS is causing slow response times, the problem shifts from query optimization to database scaling. There are multiple solutions:
1. Vertical Scaling
- Simply add more CPU and RAM
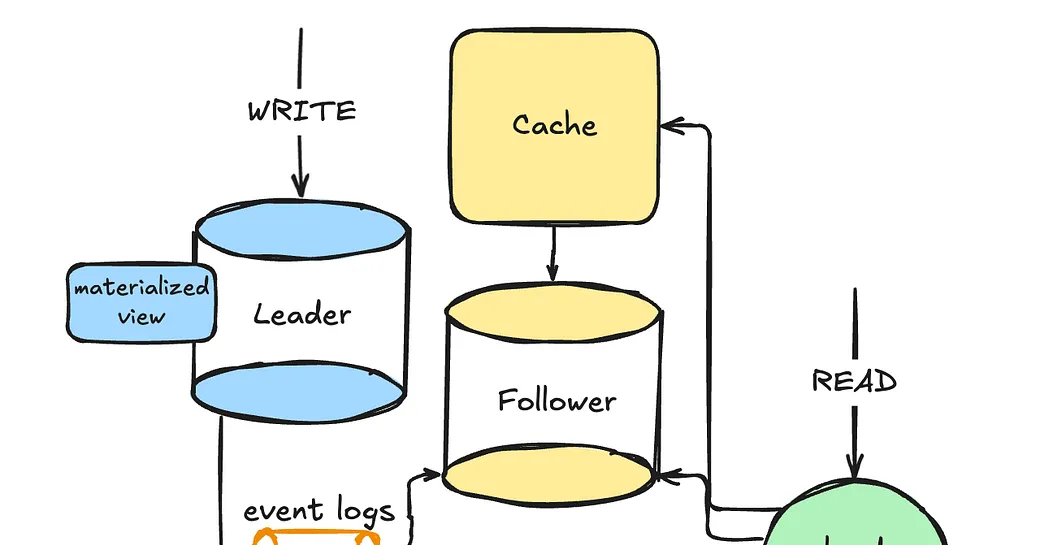
2. Read Replication (Leader-Follower Pattern)
- We set up read replicas to offload read queries from the primary database.
- A load balancer distributes reads across the replicas.
- The primary database (leader) only handles writes, ensuring better write performance.
3. Caching
- Using Redis or Memcached, frequently accessed data is stored in memory.
- This significantly reduces database load and improves response times.
- However, cache invalidation is a challenge—when the database updates, cached values must be refreshed. One approach is integrating caching into the ORM layer, where cache keys are automatically invalidated on inserts, updates, and deletes. While this can streamline cache management and improve performance, it also introduces additional complexity, increasing maintenance overhead and making the codebase more error-prone.
4. Materialized Views
- Instead of recomputing expensive queries repeatedly, the database stores precomputed results in a materialized view.
- This improves performance, especially for complex queries.
- Unlike caching, materialized views are maintained by the database, reducing consistency issues.
Interviewer: In what order would you take these actions?
- Optimize the query and indexes.
- Introduce materialized views for expensive queries.
- Evaluate vertical scaling (increasing CPU/RAM on the database server).
- Implement replication to distribute read queries.
- Use caching selectively to further reduce load.
If these steps aren’t enough, we move to more advanced scaling techniques.
Scaling Further: Beyond a Single Database
Interviewer: We’ve optimized queries, added replication, caching, and materialized views. But we still need more scalability. What now?
If we hit hardware limits on a single database, we need horizontal scaling:
1. Sharding (Partitioning Data Across Multiple Databases)
- Data is split across multiple servers based on a key (e.g., user ID).
- Each shard operates independently, reducing the load on a single database.
- Consistent hashing ensures that new shards can be added with minimal data redistribution.
2. CQRS (Command Query Responsibility Segregation)
- We separate read and write operations across different databases.
- Example: Writes go to PostgreSQL, while reads are served from Elasticsearch.
- Data synchronization is managed using Apache Kafka, ensuring eventual consistency.
Final Thoughts
This was my answer to the database scaling interview question—essentially, a self-interview. I’d love to hear other perspectives and solutions. Let me know your thoughts and feedback!