At my workplace, I was given a task: use short-lived kubeconfig for accessing Kubernetes. This was already implemented in other services in different ways, and I was asked to simply choose one of them and copy-paste it into the service I was working on. That was my plan — but when I read the code, lots of questions came to my mind about the decisions developers had made for implementing the feature.
After a while, I noticed that not only was I not copying their code into the codebase, but I was also analyzing their solutions, listing each one’s pros and cons, and even coming up with my own approach. It felt like a realistic system design interview: I was trying to identify problems, find single points of failures, and provide improvements — even if they introduced more complexity.
This blog aims to present the problem and all the solutions that came to my mind for solving it, along with their benefits and drawbacks.
Problem
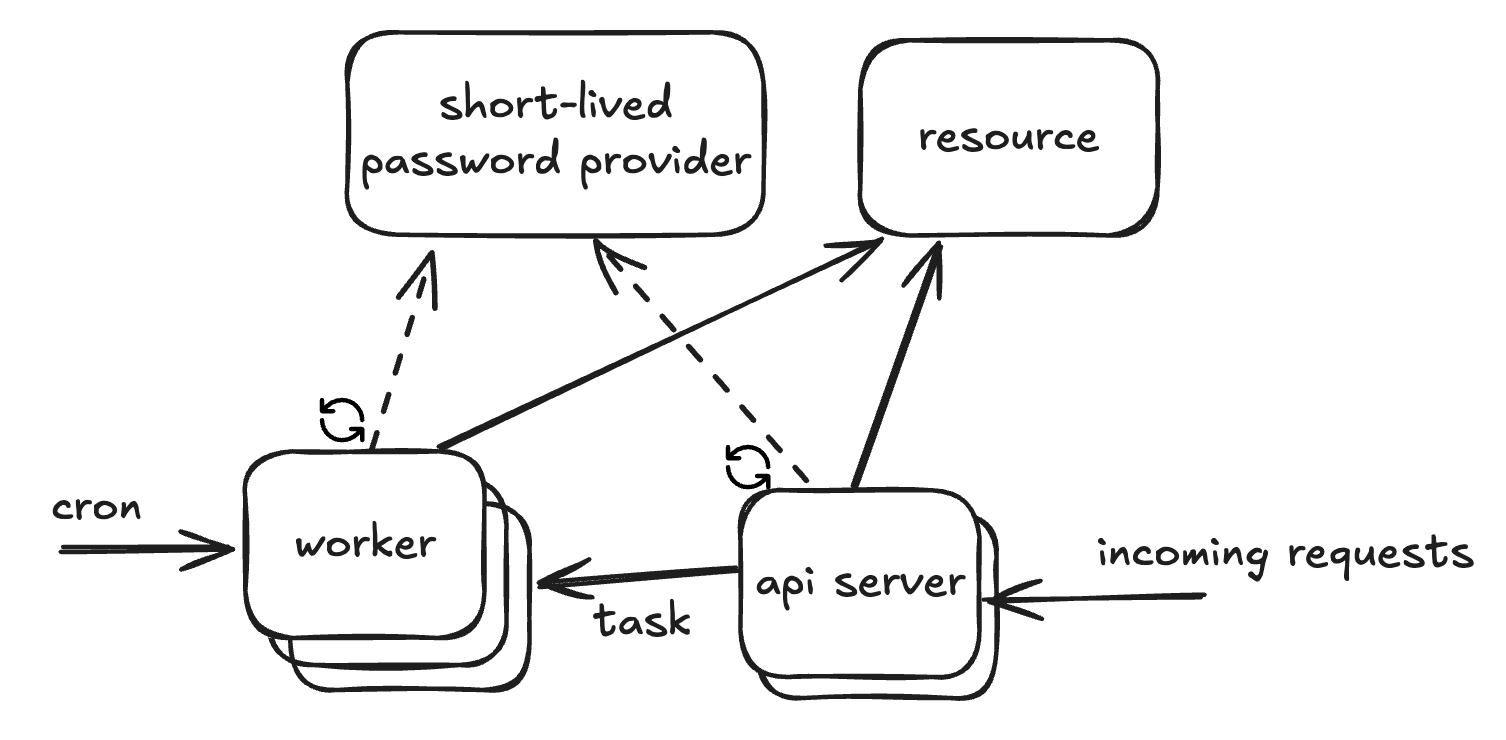
Imagine we have various services (like an API service or workers) that need to access a resource in order to perform their tasks. I’m using generic terms here to generalize the problem: the services can be APIs, workers, cron jobs, or anything else, and the resource could be a database, a Kubernetes cluster, or whatever.
The important point is: accessing the resource requires authentication.
Originally, this authentication was handled with a username/password or a token. Now, we want to make it short-lived. By short-lived, I mean it expires quickly, and you need to provide a new password or token to access the resource again.
To support this, we have a system called the short-lived password provider. You can call it to get a fresh password for the resource, valid for a default TTL. (It’s not central to the question, but worth mentioning: this provider itself also requires authentication, usually via public/private keys, mTLS, or another secure mechanism.)
The provider exposes an endpoint that returns a short-lived password for accessing the resource.
 Now let’s walk through different solutions, step by step, and see how we can improve them.
Now let’s walk through different solutions, step by step, and see how we can improve them.
1st solution: the simple API call

The easiest and most straightforward solution is to call the short-lived password provider every time we need to access the resource. This works well if our services do not use the resource frequently.
In a horizontally scaled system (with multiple nodes handling the same responsibility), each node would request its own password on each usage. Think of it like a deployment with multiple pods — each pod gets its own password whenever it needs one.
| Pros | Cons |
|---|---|
| + simple implementation | - does not take advantage of the TTL; calls the provider every time - each node calls the provider, creating high load - blocking I/O due to waiting for the provider’s response |
2nd solution: add local cache

We can improve the first design by taking advantage of the TTL. Instead of calling the provider every time, we store the password in memory (or on the node’s local storage) for the ttl duration. When it expires, we fetch a new one.
| Pros | Cons |
|---|---|
| + fewer calls due to caching + less load on the provider | - each node still calls the provider separately, so the provider may still face high load |
3rd solution: add shared cache

Instead of local cache, we can use a shared cache accessible from all nodes. This could be a shared PVC mounted into pods, or something like Redis.
The idea is similar to the 2nd solution, but now only one node needs to fetch the password from the provider — the rest can use the shared cache.
| Pros | Cons |
|---|---|
| + fewer calls to the provider + provider called only once per TTL + shared across nodes | - I/O overhead of calling shared cache each time (still faster than provider, but slower than local memory) - high load on the shared cache |
A question may cross your mind: since multiple nodes are now reading and writing to shared cache, do we need to handle concurrency or apply locks? In most cases, no — if the password provider is idempotent (always returns a valid password that doesn’t expire prematurely), then all passwords are valid and no locking is required.
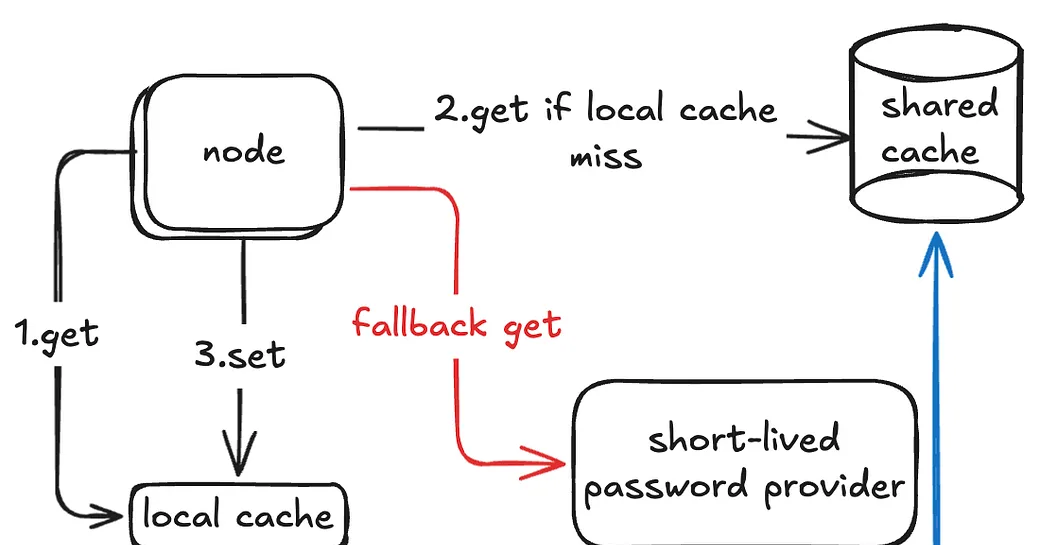
4th solution: shared and local cache together
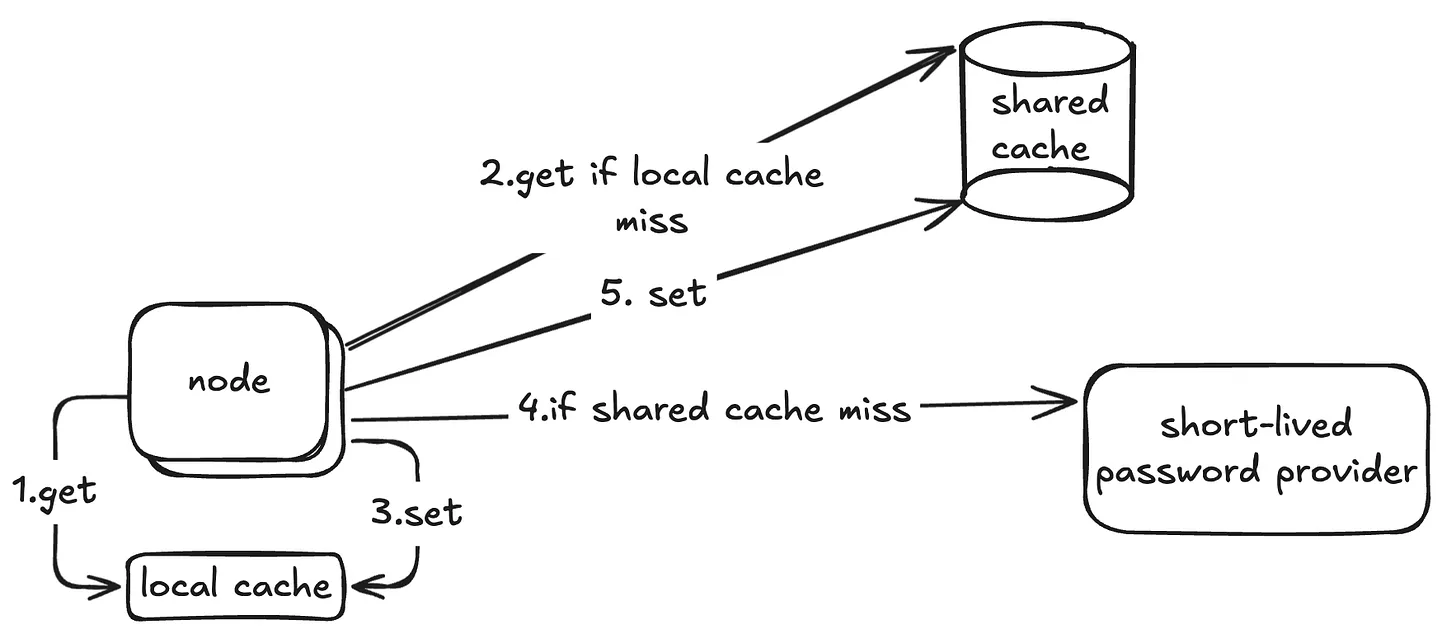
We can combine the 2nd and 3rd solutions. Each node first checks its local cache; if it misses, it checks the shared cache; if that also misses, it calls the provider.
This reduces load on the shared cache, but introduces a new issue: cache invalidation. Now we must also store the expiration time alongside the password, so that nodes know how long they can safely reuse it.
This approach also allows fallback: if the shared cache fails, nodes can still go directly to the provider.
| Pros | Cons |
|---|---|
| + efficient use of caches + fewer calls to provider + less load on shared cache + fallback if shared cache fails | - complex cache eviction and invalidation logic |
5th solution: rely on permission denied responses

Another alternative is to skip TTL handling entirely in local cache. Instead, we keep using the cached password until the resource itself denies access (e.g., HTTP 401 Unauthorized). When that happens, the node fetches a new password (first from shared cache, and if not available, from the provider).
| Pros | Cons |
|---|---|
| + no cache invalidation complexity + fewer provider calls thanks to caching + fallback if shared cache fails | - complexity of exception handling - initial request fails before refresh - potentially slower recovery |
6th solution: auto-refresh
So far, all solutions refresh the password on demand. The drawback is that the first request after expiration may be delayed.

To fix this, we can introduce an auto-refresh mechanism: a separate thread (or cron job) checks for expiring passwords and refreshes them proactively, both in local and shared cache.
| Pros | Cons |
|---|---|
| + requests always have a valid password in cache + fewer provider calls due to shared cache | - added complexity of scheduling and eviction - multithreading overhead - if the auto-refresh fails, nodes may be left with expired passwords |
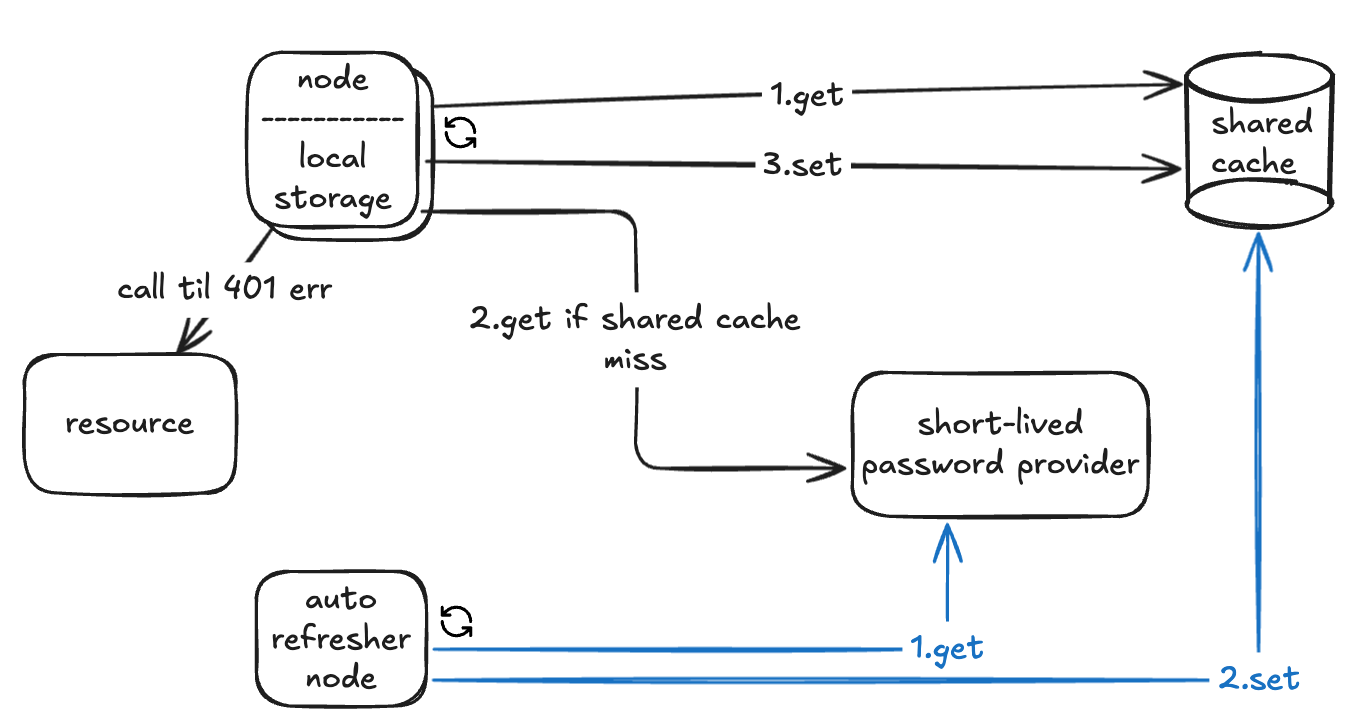
7th solution: auto-refresher node
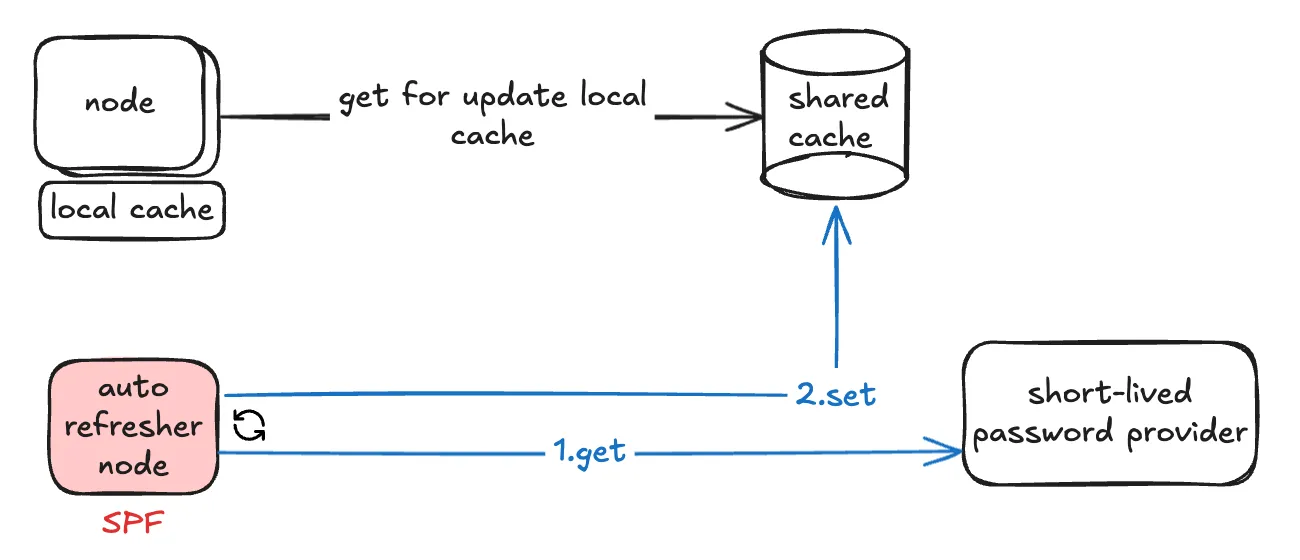 What if instead of guaranteeing that the local cache is always valid, we guarantee that shared cache is always valid, so each time the local cache expires it only gets from the shared cache and it doesn’t handle all the logic for updating the shared cache from password provider? In this case we can add another node which it’s responsibility is to periodically check shared cache and if the password is about to expire, refresh it. the local cache eviction can be either on-demand cache eviction (solution 4) or on-demand permission denied handling (solution 5).
What if instead of guaranteeing that the local cache is always valid, we guarantee that shared cache is always valid, so each time the local cache expires it only gets from the shared cache and it doesn’t handle all the logic for updating the shared cache from password provider? In this case we can add another node which it’s responsibility is to periodically check shared cache and if the password is about to expire, refresh it. the local cache eviction can be either on-demand cache eviction (solution 4) or on-demand permission denied handling (solution 5).
| Pros | Cons |
|---|---|
| + fewer calls to the provider + nodes rely only on shared cache | - single point of failure: if refresher node fails, no new passwords are fetched - added complexity of monitoring refresher health |
However this solution has a big problem. the auto-refresher node is a single point of failure and if it fails no other node can refresh the password. so lets bring a fallback mechanism for handling auto-refresher’s failure.
8th solution: auto-refresher node with fallback

To solve the single point of failure, we can give all nodes the ability to fetch from the provider if needed. The auto-refresher node still takes the main responsibility for updating shared cache, but if it fails, nodes can fall back to solutions 4 or 5.
| Pros | Cons |
|---|---|
| + efficient and resilient + refresher node reduces provider load + fallback if refresher node fails | - added complexity of monitoring refresher health - added complexity of scheduling and eviction |
Conclusion
Designing a system around short-lived credentials is all about balancing simplicity, performance, and resilience.
- If usage is rare → simple API calls may be enough.
- If usage is frequent but simple → local cache works.
- If you need efficiency across multiple nodes → shared cache (with or without local cache) is a good fit.
- If you want robustness → auto-refresh mechanisms (with fallbacks) provide better guarantees at the cost of added complexity.
In practice, there’s no single “correct” approach. It depends on your system’s requirements, scale, and tolerance for failure.
For me, what started as a “copy-paste task” turned into a mini system design exploration. And that’s the fun part of engineering: sometimes the simplest problems open the door to deeper thinking about reliability, scalability, and tradeoffs.